test

At Robosoft, many of our conversations about AI come back to an unexpected question: how language shapes power.
When I was a kid, my best friend used to go skiing in Vail every winter break. He always came back with amazing stories. I longed to be invited one year, but that invitation never came. We were inseparable, or so I thought, and from my point of view it felt personal. Eventually, I told him it bothered me. His explanation was unexpectedly practical. The kids who went on the trip only came along because their mothers were close friends of his, and because my mother was disabled, she couldn’t be invited to ski.
To make me feel better, he proposed a solution that only a child could deliver with complete confidence: since I had never been to Vail, we would simply act as though I had. We would invent our own “Vail language,” speak it in front of other people, and let everyone assume it was something we had learned together on the mountain.
At first it was nonsense. A private little stream of improvised sounds. But then something interesting happened. The babble became patterns. The patterns became repeated meanings. Before long, what started as a joke had become a small, encoded language that only the two of us understood.
That story has been on our minds lately, because it feels like a useful metaphor for what may be coming next in AI.
When people talk about AI developing its own language, the discussion usually drifts toward communication: machines talking to machines in ways humans cannot follow. That is interesting, but that may not be the real issue. The real issue is software. More specifically, whether AI creates its own language for building software that is more efficient than the human‑readable languages we have spent decades refining.
That question matters because modern programming languages are not timeless truths. They are artificial constructs that emerged in response to hardware limitations, processing constraints, storage ceilings, memory ceilings, and the expanding demands we placed on machines as those constraints slowly eased. We did not arrive at today’s programming ecosystem simply by inventing elegant syntax. We arrived here because hardware matured enough to support higher levels of abstraction.
That is why this moment feels different. AI is not approaching software the way humans did.
Google Developer Expert Laurence Svekis makes an important point when he argues that traditional programming languages were built for human use and understanding, not because machines inherently required those exact symbolic forms (Svekis, 2026). That observation opens the door to a larger conclusion: if AI does not need readability in the same way humans do, then it may not remain loyal to the structures humans prefer.
Ilya Kirnos, Partner and CTO at SignalFire, frames the history of programming as a long movement toward human readability and suggests that generative AI is now shrinking the distance between natural language and executable software (Kirnos, 2024). That may only be the midpoint of the story. Once AI becomes sufficiently fluent in our languages, it may start identifying them as inefficient baggage.
Michael Azoff, Chief Analyst at Omdia, goes even further, proposing that AI could eventually create a programming language for other AI systems rather than for human programmers (Azoff, 2026). That idea sounds futuristic until you sit with it for a minute. Of course it might. Why would a machine‑native coding language care about the things humans care about: readability, naming conventions, elegance, stylistic consistency, or maintainability in the traditional sense? A machine‑optimized language would likely value speed, compression, logic density, precision, and execution efficiency above all else.
If that happens, current languages will not vanish overnight. Python, Java, SQL, JSON, and the rest will still matter because enterprises need interoperability, auditability, governance, and trust. But their role may change dramatically. Instead of serving primarily as the medium of creation, they may increasingly serve as the medium of inspection, translation, and control. In other words, humans may continue to need these languages even as AI relies on them less.
That has major implications for the workforce. Software engineers may spend less time handcrafting code and more time setting constraints, validating outcomes, reviewing architectural decisions, and managing risk. UX practitioners may become more important, not less, because generative systems are only as good as the intent, workflows, and human outcomes they are asked to serve. As code generation becomes more automated, clarity of purpose becomes more valuable.
It also changes the delivery strategy. The opportunity is obvious: faster prototyping, shorter development cycles, lower production costs, and faster time to market. But the risks are just as real. Organizations may soon deploy systems they did not fully author, do not fully understand, and cannot easily inspect in the old way. That is not just a technical issue. It is an operational, strategic, and governance issue.
And it brings us back to that earlier story.
A private language can be efficient. It can be clever. It can create speed and advantages. But it can also conceal. The moment a symbolic system becomes useful enough that outsiders can no longer understand it, power starts to shift. That may be exactly what happens if AI begins building software through representations, abstractions, or machine‑native languages that humans can no longer meaningfully read.
If that future unfolds, then a new subtopic opens immediately behind it: how do human beings police what they can no longer directly read? How do organizations assure quality, effectiveness, safety, and ethics when the generative layer is increasingly opaque? The answer cannot simply be trust. It will require new forms of oversight, verification frameworks, interpretability tools, testing regimes, and governance models designed specifically for machine‑generated systems.
So, the question is not simply whether AI will invent its own programming language. It is simply a matter of when. And when it does happen, will human beings still be able to inspect, challenge, govern, and trust what that language creates? As an organization, we will need to do more than hope so.
If you are thinking about what that means for your organization, let’s talk.
References
Azoff, M. (2026, January 27). The day AI creates its own programming language. LinkedIn.
https://www.linkedin.com/pulse/day-ai-creates-its-own-programming-language-michael-azoff-nbzgf/
Kirnos, I. (2024, August 22). The evolution of coding: AI turns English into a programming language. SignalFire.
https://www.signalfire.com/blog/ai-evolution-of-coding
Svekis, L. (2026, February 28). Will AI create its own coding language in the future? BaseScripts.
https://basescripts.com/will-ai-create-its-own-coding-language-in-the-future

Most enterprise AI programs don’t fail because they chose the wrong model. They fail because nobody solved the harder problem first.
Your organization already possesses the answers to most of its critical business questions. They exist in contract negotiations finalized two years ago, in customer service transcripts from last quarter, in the Slack thread where your best engineer explained exactly why a product decision went wrong. The knowledge is there. The intelligence is not, because the two have never been properly connected.
This is the defining challenge of enterprise AI in 2026.
The Real Reason AI Pilots Don’t Scale
IDC research puts a stark number on the gap: only 1% of organizations have reached optimized AI maturity. The other 99% are running pilots that impress in demos and stall in production.
The conventional explanation blames data quality, change management, or unclear use cases. These are real, but they’re symptoms. The root cause is more fundamental: enterprise AI systems are being evaluated on their intelligence, while the integration layer, the infrastructure that determines what the AI can actually see, access, and act on, is treated as an afterthought.
Consider what sits outside the reach of most enterprise AI deployments today: the customer contracts living in SharePoint, the pipeline data locked in Salesforce, the financial models in SAP, the project history in Jira, the institutional knowledge exchanged daily in Slack and email. Each system has its own authentication, its own API logic, its own access controls. Connecting them isn’t a configuration task. It’s an architectural undertaking.
Organizations that treat enterprise AI as a technology purchase rather than a services engagement consistently arrive at the same destination: a sophisticated model with nowhere meaningful to look.
From Retrieval to Action: The Agentic Difference
The first generation of enterprise chatbots was built around retrieval. Ask a question, get an answer, maybe get a link.
Agentic AI operates on a different principle entirely. It doesn’t wait to be asked, it reasons, plans, and acts.
Here’s what that distinction looks like in practice. A project manager asks about the status of a deal. A retrieval-based system provides the last status update. An agentic system does something categorically different: it identifies that the project margin has dropped below threshold, checks the relevant executive’s availability in Outlook, schedules a briefing, and pre-generates a report showing margin trends and contributing factors, before a human has processed the initial answer.
The problem isn’t just flagged. The response is already in motion.
This is the shift that separates enterprise AI as a productivity feature from enterprise AI as a strategic capability. And it depends entirely on the quality of the integration layer beneath it.
Why This Is an Integration Problem, Not an LLM Problem
Choosing a large language model is the easiest decision in an enterprise AI deployment. The hard decisions come before and after: What data can the system access? Under what permissions? How does it authenticate across systems? How does it handle a workflow that spans four platforms and three departments? What happens when a step fails mid-execution?
These are not model questions. They are architecture questions, and they require a fundamentally different set of competencies to answer well.

A production-ready enterprise conversational AI system must:
- Connect securely to heterogeneous platforms with different APIs and authentication frameworks
- Understand business logic deeply enough to orchestrate coherent multi-step workflows
- Enforce role-based access controls that reflect real organizational boundaries, finance accessing financial projections, HR accessing employee records, neither accessing the other’s domain
- Maintain comprehensive audit trails that satisfy compliance and governance requirements
- Degrade gracefully when a system is unavailable or a workflow hits an unexpected state
Off-the-shelf tools don’t navigate this complexity. The organizations consistently achieving measurable returns from enterprise AI share a common trait: they invested in deep integration architecture before they optimized for AI performance.
What This Looks Like in Production
Turning 250GB of Stranded Data into a 30-Second Answer
A leading New York-based renewable energy company had a data problem that will sound familiar: large volumes of unstructured documents, siloed across multiple systems and formats, producing slow, manual, and unreliable reporting. The intelligence existed. The access didn’t.
We built a conversational analytics platform that changed the fundamental question from “who do I ask?” to “what do I want to know?” The system processes 250GB of unstructured data, makes over 3,000 documents and reports searchable through natural voice or text, and achieves 85–90% accuracy on proprietary data. Information retrieval that previously required 1–2 hours of manual effort now takes under 30 seconds.
Decision-makers can now query complex datasets in plain language, “What’s our energy production trend this quarter?” and receive accurate, sourced answers without waiting for a reporting cycle. The bottleneck between data and decision has been effectively removed.
Resolving Customer Friction at Scale
A major U.S. credit provider was absorbing a growing volume of customer complaints tied to basic account services. Customers who couldn’t or wouldn’t use the mobile app were defaulting to live agent calls for transactions that should have been self-service. Agents were overwhelmed. The experience was deteriorating.
We deployed an Intelligent Virtual Assistant using Amazon Lex and Connect that lets customers access their accounts through natural conversation, by phone or chat, in English or Spanish. The system handles authentication, balance inquiries, payments, and account updates without agent involvement. Agent workload dropped significantly as routine queries shifted to self-service, and the architecture is built to scale conversational AI across both voice and chat channels as the business grows.
Rebuilding HR Operations Around Intelligence
A services organization replaced its fragmented HR workflows with a coordinated system of five specialized AI agents, each purpose-built for a distinct function within talent operations.
The results were structural, not incremental. HR query response time dropped from hours to seconds. Candidate matching shifted from keyword filtering to vector-based skills and experience analysis, surfacing better-fit candidates earlier in the pipeline. Automated agents now handle job description generation, resume standardization, and candidate gap analysis, work that previously consumed recruiter time that could have been spent on relationship-building and strategic hiring decisions.
The team didn’t just get faster. They got to do different, higher-value work.
The Governance Imperative
Enterprise conversational AI systems access sensitive data and execute actions on behalf of employees. The governance architecture is not optional; it is the system.
Role-based access control must be enforced at the integration layer, not the application layer. This means connecting to identity and access management systems, defining and enforcing permission policies that reflect real organizational structure, and maintaining audit trails detailed enough to answer the question “who accessed what, when, and why” under regulatory scrutiny.
Permissions must also be dynamically updated as roles change, as organizational structures evolve, and as new data sources come online. Static governance frameworks become liabilities in organizations that move fast. The architecture must move with them.
The Path from Pilot to Production
The organizations that successfully scale enterprise AI share a consistent pattern. They start with a specific, measurable business problem.
“Reduce customer service resolution time by 40%” is a strategy. “Implement conversational AI” is a purchase.
From there, the progression looks like this:
Assess before you build
Can your critical systems be accessed programmatically? Is your data governance consistent enough to support AI workflows? Are your authentication frameworks ready for agent-level access? These questions determine your actual starting point, which is often different from where leadership assumes the organization is.
Win where the integration is tractable
Internal knowledge access and employee-facing workflows are higher-value, lower-complexity starting points than customer-facing or regulated use cases. Prove the model internally before exposing it externally.
Measure what matters
Task completion rates, time saved per workflow, reduction in manual escalations, direct impact on business outcomes. AI accuracy is a proxy metric. Business impact is the real one.
Build for continuous improvement
The organizations extracting the most value from conversational AI have stopped thinking of it as a project. They have cross-functional teams iterating on the system continuously, based on user behavior, new data sources, and evolving business priorities.
The Window Is Open, But Not Indefinitely
Early adopters of agentic enterprise AI are accumulating a structural advantage: faster decisions, lower operational overhead, and compounding returns as their systems learn and expand. Organizations still operating basic retrieval chatbots are not standing still; they are falling behind relative to competitors who have solved the integration problem.
The question is no longer whether conversational AI belongs in the enterprise. It does. The question is whether your organization will treat it as a technology feature or an architectural capability, and whether you have the right partner to build it properly from the ground up.
Robosoft Technologies designs, builds, and deploys production-grade conversational AI systems for enterprises that are ready to move beyond pilots. Our work sits at the intersection of deep integration architecture, AI orchestration, and enterprise governance because that’s where the real returns are.
Your data already holds the answers. Let’s build the AI systems to unlock them. Connect with our Data & AI team.

As digital products evolve into complex, interconnected systems, experience can no longer be treated as a surface layer applied at the end of development. It must be intentionally designed, rigorously built, and continuously improved. For leaders navigating platform modernization, digital transformation, and AI adoption, this shift is imperative.
At Robosoft Technologies, we call this Engineering Human Experiences, combining human insight, product thinking, and enterprise‑grade engineering to build digital systems that are meaningful, resilient, and built for impact.
The growing role of AI in design is accelerating this shift. Not by replacing creativity, but by changing how experiences are engineered, scaled, and governed across organizations.
What we increasingly see in enterprises is AI being added to the design workflow without changing how experience decisions are governed. The result is more output at higher velocity. However, this does not necessarily lead to better experiences, because consistency, accessibility, performance, privacy, and trust still depend on rigorous operating standards rather than tool adoption.
Experience is a system
Today’s digital experiences are shaped by far more than interfaces. They are shaped by intelligent systems driven by data and AI, platforms that must scale securely and reliably, and users who expect clarity, trust, reliability, and empathy at every interaction.
A travel rebooking, a password reset, or a content search through filters are all moments of user interaction, in which the system demonstrates whether it understands intent, respects data, and makes discovery effortless. Design choices inside these moments are engineering choices; they either strengthen the system or create friction.
In this context, experience is not a deliverable. It is a system. AI in design makes that system more observable and adaptable, but only when it is backed by robust engineering practices.
Design decisions now directly affect:
- Performance: latency, responsiveness, system load
- Accessibility: inclusive experiences across users and contexts
- Compliance: regulatory and data obligations
- Long‑term scalability: consistency across platforms and regions
Treating experience as an engineering discipline is no longer optional; it is essential.
How AI strengthens the design lifecycle
AI is increasingly embedded across the design lifecycle, from research and exploration to validation and optimization. When applied thoughtfully, AI improves the operating quality of design by shortening feedback loops and making experience performance observable across systems, not just screens.
In practice, teams can interrogate behavioral signals at scale, pressure‑test more variants across more user contexts, and surface experience risks earlier before they become expensive fixes in engineering or support. AI also strengthens design‑system consistency by detecting drift across components, patterns, and platforms as products scale.
In delivery, AI can surface accessibility risks, suggest performance‑aware alternatives for latency‑sensitive flows, and support safer testing. The impact is not simply faster design but fewer late‑stage rework cycles, more predictable releases, and higher experience consistency across teams and products.
AI in design and the role of judgement
AI in design does not automatically create better experiences. Without human context, product judgment, and engineering rigor, AI‑generated outputs risk becoming generic, fragmented, or misaligned with real user needs.
AI tools are effective at optimizing for what has worked before. Still, they do not understand emotional nuance, situational stakes, or trust dynamics, for example, a user making a high‑risk financial or procurement decision. Those moments require human judgment: understanding why users behave the way they do and what truly matters in context.

What engineering human experiences actually mean
At Robosoft, we believe the future of design is grounded in engineering human experiences, not automating creativity. This means designing with empathy and purpose, building scalable and resilient systems, embedding quality, privacy, and performance from the start, and ensuring experiences can evolve responsibly over time.
AI for Design and Design for AI
At Robosoft, we approach AI and experience design through two complementary lenses, and we actively work across both:
AI for Design
Using AI to make the design process more efficient and productive by accelerating research, exploration, validation, and design‑system consistency so teams can focus on higher‑order decisions and complex experience challenges.
Design for AI
Designing AI‑native products and platforms, including experiences that support agentic behavior responsibly. This means designing how users set intent, how autonomy is bounded, how exceptions are handled, and how trust is maintained through clarity, control, and accountability.
Both are required. AI for Design improves productivity. Design for AI determines whether AI‑enabled experiences remain usable, governable, and trusted at scale.
The disciplines behind engineered experiences
In practice, engineering human experiences rests on four disciplines:
- Empathy: deep research that goes beyond usability to understand behavioral and emotional context
- Engineering rigor: treating accessibility, performance, privacy, and compliance as design requirements
- Governance: principles, standards, and controls that scale across teams and products
- Accountability: connecting design decisions to measurable business outcomes
AI becomes a powerful enabler within this framework, accelerating insight and execution, while engineering ensures trust, reliability, and durability.
Why scale makes governance a differentiator
As organizations scale, isolated design efforts break down quickly. Experience must operate across products, platforms, devices, regions, regulations, and user segments.
AI in design can increase adaptability and consistency at scale, but scale also raises the cost of inconsistency. Governance becomes a performance advantage: clear principles, shared standards, and engineering‑grade quality controls that hold across teams, products, and markets.
This is where experience, software, data, and AI must operate as one system.
The path forward
AI in design will continue to evolve. Tools will change. Expectations will rise. What will endure is the need to engineer experiences that solve real user problems and drive measurable business outcomes.
For leaders evaluating how AI can strengthen digital experiences without weakening trust, clarity, performance, or governance, the practical question is whether the organization is building both:
- AI for Design: productivity in how experiences are created
- Design for AI: AI‑native experiences that remain accountable at scale
Robosoft Technologies partners with enterprises to engineer human experiences by combining human insight, product thinking, and enterprise‑grade engineering, so that experience quality improves as systems scale, and AI adoption deepens.
If you’re looking to embed this approach into your transformation vision to engineer human experiences at scale, we’d be glad to start that conversation.

At Robosoft Technologies, we work with global enterprises navigating the shift from digital transformation to enterprise‑scale AI adoption. Across industries, we see a consistent pattern: while Generative AI has delivered measurable productivity gains, many organizations struggle to convert AI‑driven intelligence into execution at scale.
Our experience building and scaling complex digital platforms where experience design, engineering, data, and operations converge has shown us that the next phase of enterprise AI will not be defined by better answers alone. It will be defined by AI systems that can act, adapt, and execute responsibly within real business environments.
This perspective shapes how we view the growing distinction between Generative AI and Agentic AI, and why this distinction is becoming increasingly important for enterprise leaders.
Over the past two years, Generative AI adoption has accelerated rapidly. AI copilots, chatbots, and content engines are now embedded across marketing, customer service, product development, and IT teams. These systems have improved speed, efficiency, and access to information. Yet for many CIOs and digital leaders, a fundamental limitation is becoming clear: execution still depends heavily on humans.
Generative AI can generate insights, content, and recommendations, but people continue to coordinate workflows, manage handoffs, resolve exceptions, and drive outcomes across enterprise systems. The gap between AI‑generated output and business execution remains largely manual.
This execution gap has led to the emergence of Agentic AI, a new class of AI systems designed to move beyond generation and into autonomous execution. As enterprises shift from AI experimentation to scaled deployment, understanding the difference between Agentic AI and Generative AI is no longer optional.

To understand generative AI vs agentic AI, it helps to start with what Generative AI does best.
Generative AI represents a major advancement in how organizations work with data and knowledge. It excels at creating text, code, images, and summaries, and delivers value across customer support, content creation, personalization, and software development. Its core strength lies in fluency and pattern recognition.
However, Generative AI is inherently reactive and prompt‑driven. It operates within defined tasks and requires human direction to move work forward. While it augments individual productivity, it does not independently plan or execute multi‑step business processes. As a result, it enhances work but does not fundamentally change how workflows through the enterprise.
Agentic AI builds on Generative AI and machine learning but introduces goal‑directed autonomy. Instead of responding to prompts, agentic systems are designed to understand objectives, decompose them into tasks, and initiate actions across enterprise applications. These systems can adapt to changing conditions, retain context over time, and learn from execution outcomes.
In practice, Agentic AI behaves less like an assistant and more like a digital execution layer. It can take a business goal, determine the required steps, interact with APIs and data sources, monitor progress, and adjust its approach in real time. Over time, it builds institutional memory and improves decision‑making.
The distinction becomes clear in real enterprise use cases. In sales operations, Generative AI may draft outreach emails or summarize account data. Agentic AI can go further researching prospects, prioritizing leads, personalizing communication, updating CRM systems, scheduling meetings, and escalating risks autonomously.
In procurement, agentic systems can evaluate suppliers, compare quotes, generate purchase orders, and trigger approvals. In recruitment, they can screen candidates, schedule interviews, and manage follow‑ups. In finance and compliance, they can support audit preparation, policy checks, and exception handling.
These are not isolated automations. They represent end‑to‑end workflow ownership. In more advanced scenarios, multiple AI agents operate together as a coordinated system. One agent may monitor inventory, another forecast demand, another negotiate with vendors, and another manage logistics. These agents share context, collaborate, and adapt dynamically much like a cross‑functional human team.
For enterprise leaders, this distinction directly impacts AI investment strategy. Generative AI is best suited for use cases focused on creation, insight, and communication. Agentic AI becomes essential when the objective is execution, coordination, and measurable business outcomes.
Organizations that rely solely on Generative AI will continue to see incremental productivity gains. Those that adopt Agentic AI will begin to reshape operating models, reduce decision latency, and lower the cost of coordination. This marks a shift from AI‑assisted work to AI‑enabled execution.
Agentic AI also introduces new challenges. These systems are still maturing and require careful architectural design. Persistent memory, planning logic, orchestration, monitoring, and fail‑safe mechanisms are critical. As autonomy increases, governance, accountability, transparency, and human oversight become even more important.

At Robosoft, we don’t look at Agentic AI as just another technology layer it’s a transformational enterprise capability. Through our work across digital experience, platform engineering, and data ecosystems, we’ve seen that the real value of autonomous AI doesn’t come from adding more agents. It comes from knowing where autonomy truly drives leverage and where human judgment must remain at the center.
AI for the enterprise must be designed to scale, integrate, and prove measurable ROI. Without that, Agentic AI risks becoming just a collection of isolated agents solving narrow tasks useful, but not a real differentiator for the business.
That’s why we focus on reimagining how workflows through the organization, rather than simply layering AI on top of existing processes. We combine Generative AI for insight and expression with Agentic AI for execution, built on architectures that are scalable, governed, secure, and aligned to tangible business outcomes.
The next phase of enterprise AI won’t be defined by who can generate the best answers, it will be defined by who can execute better, faster, and more intelligently at scale, with AI embedded into the operating fabric of the organization.
For enterprise leaders, the question is no longer whether to adopt AI. The real question is how to design AI systems that can operate responsibly at scale, deliver measurable value, and continuously improve over time.
At Robosoft, we partner with CIOs and digital leaders to identify where autonomy can create meaningful impact across workflows, platforms, and customer journeys while ensuring the right balance of governance, control, and human oversight.
If you’re rethinking how AI fits into your operating model and want to move beyond experimentation toward enterprise-grade, ROI-driven AI, we’d be glad to start that conversation.

Artificial Intelligence (AI) has moved beyond being just a buzzword we first heard in the movie The Matrix two decades ago. AI is here. It is no longer confined to conferences, boardroom discussions, or LinkedIn feeds; it is now embedded in our phones, financial systems, factories, and customer service platforms. Yet, despite its ubiquity (and immense hype), relatively few organizations have been able to leverage AI beyond proof-of-concepts or pilots.
The gap between the buzz surrounding AI and its impact is staggering. McKinsey estimates that Generative AI (GenAI) could unlock $2.6 to $4.4 trillion in economic value annually across industries. Capturing that value, however, will depend on knowing how to identify AI use cases that align with real business priorities and build upon the potential of other AI technologies.
The first critical step in unlocking real business value from AI investments is typically missed—framing the right AI use cases. Gartner predicts that by 2026, almost 80% of enterprises will have used Generative AI APIs or models and deployed GenAI-enabled applications. Yet only a fraction will see material ROI unless they have framed the right AI use cases.
This makes the question of how to identify AI use cases in business critical for AI leaders shaping digital and competitive strategy. In this article, we’ll break down how to frame the right AI use cases that bridge the gap between curiosity and business outcomes.
Why identifying AI use cases matters

- Technology-first bias: Many AI initiatives start with a technology-first mindset (“Let’s use AI”) instead of a problem-first mindset (“Here’s the problem we need to solve”). Jumping straight into AI without defining a clear problem to solve may result in impressive tech demos that may or may not survive beyond the pilot stage.
- Outcome-driven adoption: The reality is that AI only delivers value when it moves beyond hype into clear, well-framed use cases that drive measurable business outcomes.
How to identify AI use cases in business
When executives ask, “Where should we apply AI?”, aligning AI to strategic business outcomes is the right answer. Below are the steps on how to identify AI use cases in business to ensure your AI initiatives balance value creation with implementation feasibility:
1. Choose outcomes over algorithms
Every organization tends to drive specific business outcomes. Identifying those strategic priorities and building a case around them is essential. These priorities could be improving customer retention, reducing operational costs, improving decision-making, driving cross-sell, or improving gross margins—and then exploring where and how AI can play a role.
The question is not “What can AI do?” but “What can AI do for us?” An organization needs to know where AI can make a measurable impact.
2. Identify high-impact, high-feasibility areas
Not every business problem is ready for AI. The sweet spot often lies in challenges that are evaluated along two pivots:
- Impactful: Meaningful ROI or competitive advantage
- Feasible: Availability of quality data, supportive infrastructure, and change readiness
Identifying real-life solvable AI use cases is crucial as it adds commercial value and improves AI adoption within the organization.
3. Frame the use case in a business-friendly way
A well-framed AI use case is more than a technical description. It must answer four key questions:
- Who benefits from the solution? (e.g., sales, customers, operations, customer service, etc.)
- What problem is being solved?
- How does AI create value? (e.g., faster, cheaper, safer)
- What measurable outcomes will be achieved? (e.g., cost savings, revenue lift, risk reduction, etc.)
4. Balance innovation with practicality
There is nothing wrong with cutting-edge AI. However, a healthy AI portfolio should have:
- Quick Wins: Low-complexity projects delivering fast ROI
- Strategic Bets: Medium to long-term projects that can reshape the business model (e.g., AI-driven product personalization)
- Foundational Bets: A list of foundational initiatives that create a base for future transformations with AI
This ensures that the AI journey has both momentum and transformative potential.
5. Build for adoption, not just deployment
Even the best AI model can fail if nobody uses it. Therefore, your successful AI use case must plan for:
- Change management (training, stakeholder buy-in)
- Integration into workflows
- Ongoing monitoring (performance, ethics, compliance)
According to McKinsey’s Superagency in the workplace’ report, 92% of companies plan to increase AI investments in the next three years. Still, only 1% of executives believe their organization is mature in AI adoption and deployment. This indicates a gap rooted in the misalignment between identifying and scaling AI use cases.
Final thought
AI is not a magic wand – it is a tool. Its business impact depends entirely on how well you identify, frame, and prioritize AI use cases. By starting with outcomes, focusing on feasible high-value problems, and framing use cases in plain business language, organizations can not only move beyond the buzzword but also gradually start leveraging AI as a driver of competitive advantage. The organizations winning with AI are not the ones with the most algorithms, but those with the clearest intent and best-framed AI use cases.

This article explores how AI revolutionizes legacy application modernization for B2B organizations in industries like finance, healthcare, and manufacturing. Discover how AI automates code refactoring, predictive maintenance, data migration, and more to reduce technical debt, enhance agility, and drive innovation. Learn from real-world use cases, best practices, and strategies to overcome challenges, empowering CTOs, IT managers, and business owners to future-proof their operations.
The legacy system challenge in B2B
Legacy systems—outdated software and hardware still critical to operations—are a cornerstone of B2B industries like finance, healthcare, and manufacturing. Industry data suggests over 70% of enterprises rely on these systems, often decades old, to power core functions. However, they present significant challenges:
- High maintenance costs: Legacy systems consume up to 80% of IT budgets due to specialized support and frequent patching.
- Operational inefficiencies: Slow performance and a lack of integration with modern technologies like cloud or IoT hinder productivity.
- Barriers to digital transformation: Incompatibility with new platforms stalls innovation and slows time-to-market.
Artificial Intelligence transforms legacy system modernization by automating complex tasks, reducing costs, and enabling seamless transitions. This handbook outlines how AI empowers B2B leaders to modernize efficiently while maintaining operational continuity.
What is legacy application modernization?
Legacy application modernization involves updating or replacing outdated software to align with modern technologies, improve performance, and meet evolving business needs. This can include rehosting, re-platforming, refactoring, or rebuilding applications to leverage cloud, AI, and other innovations. AI accelerates this process by automating manual tasks, minimizing risks, and enhancing scalability. Unlike traditional approaches, AI-driven modernization delivers precision and efficiency, making it a strategic tool for B2B organizations.

How does AI help modernize legacy systems?
AI addresses the core challenges of legacy system modernization by automating processes, improving decision-making, and ensuring compatibility. Its key capabilities include:
- Code Analysis & Refactoring: AI tools like GitHub Copilot or IBM’s modernization suites analyse legacy code (e.g., COBOL, Fortran) and automate conversion to modern languages like Java or Python, reducing manual effort by up to 40%. AI excels at analysing large codebases to map dependencies, identify dead code, and understand system architecture. Machine learning models parse millions of lines of code to create visual dependency graphs, detect patterns, and highlight areas of technical debt, significantly reducing the time needed for system assessment.
- Automated Code Migration: AI-powered tools translate code between programming languages and frameworks, such as converting COBOL to Java or migrating from monolithic architectures to microservices. These tools understand syntax patterns and business logic, maintaining functional equivalence while updating the technology stack. Human oversight ensures accuracy, but AI handles much of the mechanical translation work.
- Data Migration and Transformation: AI automates data cleansing, schema mapping, and migration to modern platforms, ensuring data integrity with minimal errors. Natural language processing (NLP) extracts business rules embedded in old documentation or code comments, making them explicit for new systems. AI also transforms outdated data formats into modern structures, addressing decades of accumulated data complexity.
- System Integration and API Generation: AI analyses legacy system interfaces and generates modern APIs to wrap older functionality, enabling gradual modernization. Legacy systems can continue operating while exposing capabilities through contemporary interfaces. Machine learning models predict optimal integration patterns based on system usage, ensuring seamless communication with modern platforms.
- Testing and Quality Assurance: AI generates comprehensive test suites, including edge cases often missed in manual testing. By analysing historical system behaviour and user interactions, AI creates realistic test scenarios to ensure modernized systems maintain functional parity with their predecessors.
The key advantage of AI in legacy modernization is its ability to process vast amounts of code, documentation, and system behaviour patterns at scale, providing insights that would be impractical to gather manually. This enables informed modernization decisions and reduces the risk of losing critical business logic during the transition.
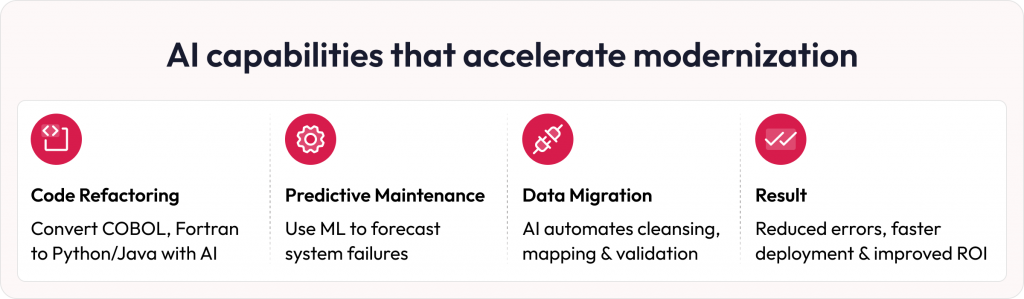
Real-world use cases of AI in legacy modernization
AI-driven modernization is delivering tangible results across B2B sectors. Here are compelling examples:
- Retail – McDonald’s: The fast-food leader modernized its mobile app and kiosks using AI and cloud technologies. AI-driven analytics optimized user interfaces, boosting digital order volumes by 20% and enhancing customer experiences.
- Banking Sector: A global bank used AI-powered chatbots and predictive analytics to modernize its legacy customer service systems. This reduced operational costs by 15% and improved customer satisfaction through faster issue resolution.
- Healthcare – Cleveland Clinic: The clinic scaled its telehealth platform by modernizing legacy systems with AI-driven data integration, enabling seamless patient data access and increasing telehealth adoption by 25%.
These cases demonstrate how AI aligns with B2B goals of efficiency, cost savings, and superior customer outcomes, reinforcing its role in legacy modernization trends.
How does AI overcome modernization challenges?
Modernizing legacy systems involves hurdles like compatibility issues, data migration risks, and stakeholder resistance. AI provides targeted solutions:
- Compatibility Issues: AI tools conduct automated compatibility testing and generate API wrappers to integrate legacy systems with modern platforms, ensuring seamless communication. Machine learning predicts optimal integration patterns, reducing friction during transitions.
- Data Migration Risks: AI automates data validation and cleaning, reducing errors. Generative AI creates digital twins—virtual system replicas—to simulate updates risk-free, minimizing disruptions. NLP extracts embedded business rules, ensuring no critical logic is lost.
- Stakeholder Resistance: AI-driven analytics quantify ROI, demonstrating benefits like reduced costs or faster time-to-market to gain stakeholder buy-in. AI also generates comprehensive documentation, including business logic explanations and system architecture diagrams, addressing the loss of institutional knowledge.
- Regulatory Compliance: In regulated sectors like finance and healthcare, AI-powered governance frameworks ensure compliance with standards like GDPR or HIPAA during modernization.
- Knowledge Transfer and Documentation: AI analyses legacy code to generate API documentation, system architecture diagrams, and training materials for new systems. This mitigates the loss of operational knowledge and creates runbooks for modernized environments.
- Quality Assurance at Scale: AI generates test cases covering obscure edge cases and realistic production scenarios. It verifies behavioural equivalence between legacy and modernized systems, detecting discrepancies that could indicate missing business logic.
- Resource and Timeline Optimization: AI models trained on historical modernization projects provide accurate effort estimates by analysing codebase complexity and technical debt. Automated refactoring improves code maintainability while preserving functionality, reducing manual effort.
- Technical Debt Management: AI prioritizes modernization efforts by analysing change frequency, bug density, and business value, focusing on high-ROI areas. It supports gradual migration through hybrid architectures, managing data synchronization across mixed environments.
The fundamental advantage is that AI processes system complexity at a scale unmatched by human teams, providing analytical rigor for confident modernization decisions rather than guesswork. Partnering with AI experts is critical to navigating these challenges effectively.

Best practices for B2B leaders in AI-driven modernization
To maximize AI’s impact on legacy application modernization, B2B leaders should adopt these best practices:
- Conduct a System Audit: Assess legacy systems to prioritize high-value applications critical to business outcomes, such as customer-facing platforms.
- Adopt a Phased Approach: Implement modernization in stages (e.g., rehosting, then refactoring) to minimize disruptions and allow iterative improvements.
- Leverage AI-Driven Tools: Use platforms like GitHub Copilot for code refactoring or Stride 100x for automated testing to accelerate and streamline modernization.
- Align with Business Goals: Link modernization efforts to outcomes like faster time-to-market, enhanced customer experiences, or cost reductions.
- Upskill Teams: Invest in training to bridge skill gaps in AI and modern architectures, empowering teams to support new systems.
These strategies ensure modernization delivers measurable value while minimizing risks.

The future of AI-driven modernization
AI is reshaping legacy system modernization by enabling faster, more cost-effective transformations. Emerging trends include:
- Integration with IoT: AI and IoT enable real-time monitoring and predictive maintenance in modernized manufacturing systems.
- Blockchain for Security: AI-driven modernization incorporates blockchain to enhance data security, critical for industries like finance.
- Low-Code Platforms: AI-powered low-code platforms simplify application development, reducing reliance on legacy systems.

Embracing generative AI in application modernization positions B2B organizations to stay agile and competitive in a rapidly evolving landscape. Ready to transform your legacy systems with AI? Engage with AI experts to reduce technical debt, boost efficiency, and future-proof your B2B operations.
FAQs: AI in legacy modernization
- What is AI modernization?
AI modernization uses artificial intelligence to update legacy systems, automating tasks like code refactoring, data migration, and testing to enhance performance and align with modern business needs. - What is an example of legacy modernization?
A financial institution modernizing its COBOL-based mainframe with AI-driven code conversion and data migration to a cloud-native platform, enabling real-time account access and personalized services. - What is the role of AI in the modern era?
AI drives innovation by automating complex tasks, enabling data-driven decisions, and enhancing scalability, making it essential for AI in digital transformation and legacy modernization. - How can businesses automate legacy modernization?
Businesses can use AI tools like GitHub Copilot for code refactoring, ML models for predictive maintenance, and automated ETL tools for data migration to streamline modernization. - What are the benefits of legacy system modernization?
Modernization reduces maintenance costs, improves agility, enhances customer experiences, and enables integration with modern technologies like cloud and IoT.

Agentic Integrated Development Environments (IDEs) are transforming software development in 2025 by embedding AI-powered assistance directly into everyday coding workflows. These intelligent tools streamline development cycles, simplify debugging, enhance deployment processes, and significantly boost developer productivity.
This shift isn’t just about keeping up with the latest tech trends; it’s a pragmatic response to the continuous demand for speed, efficiency, and innovation. Let’s explore what’s ahead and why delivery leaders must lean into this change.
What is AI assisted software development?
AI assisted software development refers to the use of artificial intelligence tools and models to support developers throughout the development lifecycle. These systems don’t just autocomplete lines of code, but they understand context, suggest improvements, and even generate blocks of code based on intent.
These AI models operate quietly in the background, scanning the codebase, understanding developer behavior, and offering intelligent recommendations for syntax, structure, refactoring, or even unit test creation. The goal isn’t to replace the developer, but to reduce friction and accelerate high-quality output.
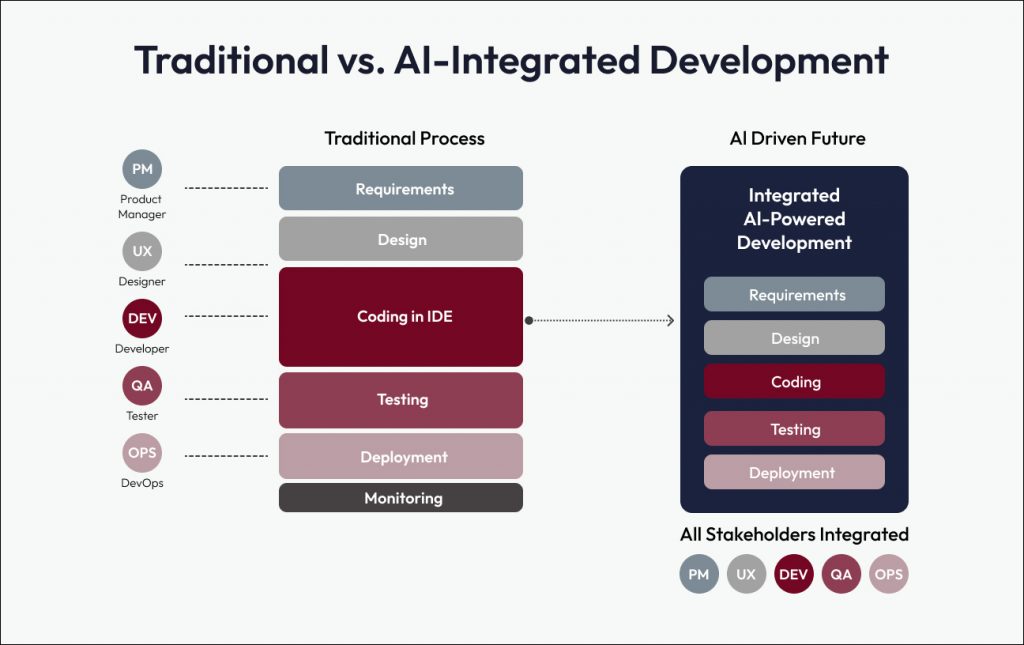
Agentic IDE transforming software development
AI assistants such as GitHub Copilot, Amazon CodeWhisperer, and Replit Ghostwriter now play an integral role in software development workflows. These models can generate boilerplate, refactor code, and even write complete functions by interpreting inline comments and contextual cues. Developers are also beginning to use natural language prompts to describe their intent. This allows the IDE to generate or modify code in real time, much like working alongside a smart colleague.
This shift redefines the IDE as an intelligent partner in the development process – understanding context, anticipating needs, and accelerating delivery. Let’s explore how this transformation is reshaping the future of software delivery and what it means for teams ready to embrace AI-assisted development at scale.
Agentic IDEs: from co-pilot to autonomous development
The development workflows are becoming increasingly autonomous with agentic AI. These agents can:
- Break down business requirements.
- Write tests and validate functionality.
- Refactor or optimize code autonomously.
Multi-agent frameworks (like AutoGPT or Devin) will execute tasks across the SDLC. The impact is significant: developers will guide these agents with prompts, monitor results, and focus more on orchestration than implementation.
Here’s how these agents are improving developer workflows:
- Natural language interaction: developers describe what they need in plain English, and the agent works to implement it.
- Multi-step problem solving: complex tasks are broken into manageable steps, distributed across functions or files.
- Contextual understanding: agents retain context across sessions to provide smarter, more relevant output.
- Codebase navigation: large codebases can be explored using natural language, making it easier to locate and understand logic.
- Debugging assistance: AI analyzes errors and suggests potential fixes based on past patterns.
- Planning and architecture support: agents help make high-level design decisions and implementation strategies.
- Chain of thought reasoning: agents explain their reasoning, making their actions interpretable and easier to trust.
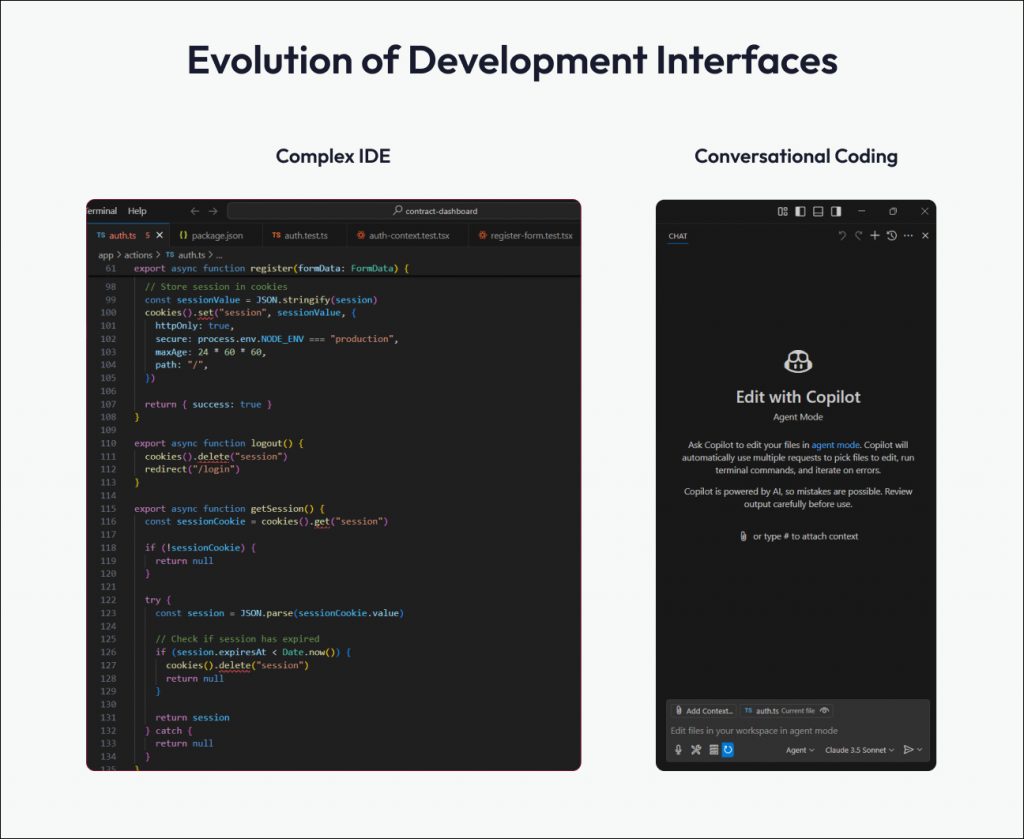
Image: Right side shows agent mode window where developers can delegate code editing, debugging, and command execution.
Building blocks: modular, API-first, and composable architectures
As AI assisted software development matures, the underlying architecture must evolve to support its speed and modularity. The future development will shift to composing solutions from modular services (micro frontends, microservices, reusable SDKs). Rather than building end-to-end monolithic applications, development is moving toward API integration, orchestration, and service mesh.
Also, read how MACH architecture enables agile and scalable digital solutions.
Rise of low-code no-code with pro dev integration
As platforms become more composable and modular, low-code, no-code development is gaining serious traction. Business users and domain experts can now prototype applications quickly using platforms like OutSystems or Mendix.
The role of professional developers is evolving. Pro developers are increasingly taking on responsibilities such as:
- Extending low-code prototypes with custom logic and integrations.
- Scaling applications for performance, reliability, and maintainability.
- Embedding security, compliance, and governance into the development lifecycle.
This shift positions experienced engineers as platform enablers and governance architects, ensuring low-code innovation doesn’t compromise software quality or technical integrity.
Cloud-native and edge-optimized development
In an AI assisted development environment, agility and scalability are non-negotiable. That’s why cloud-native architectures and edge-optimized deployments are becoming the new default. Everything will be developed and deployed cloud-first. Real-time apps will leverage serverless functions, edge compute, and global CDNs. Developers will use Infrastructure as Code (IaC) tools and AI-optimized DevOps workflows.
Shift-left and autonomous testing
Quality no longer waits for a dedicated QA phase. In an AI assisted software development lifecycle, testing shifts left. It is enabling real-time, autonomous testing by:
- Auto-generating and executing test cases as code is written.
- Performing mutation testing and behavioral coverage analysis.
- Developers will treat testing as continuous assurance, not a separate phase.
AI-driven testing is moving toward comprehensive scenario generation, including edge cases that human developers might miss. Future tools will likely generate entire test pyramids, from unit tests to end-to-end scenarios, while maintaining test data and managing test environments automatically.
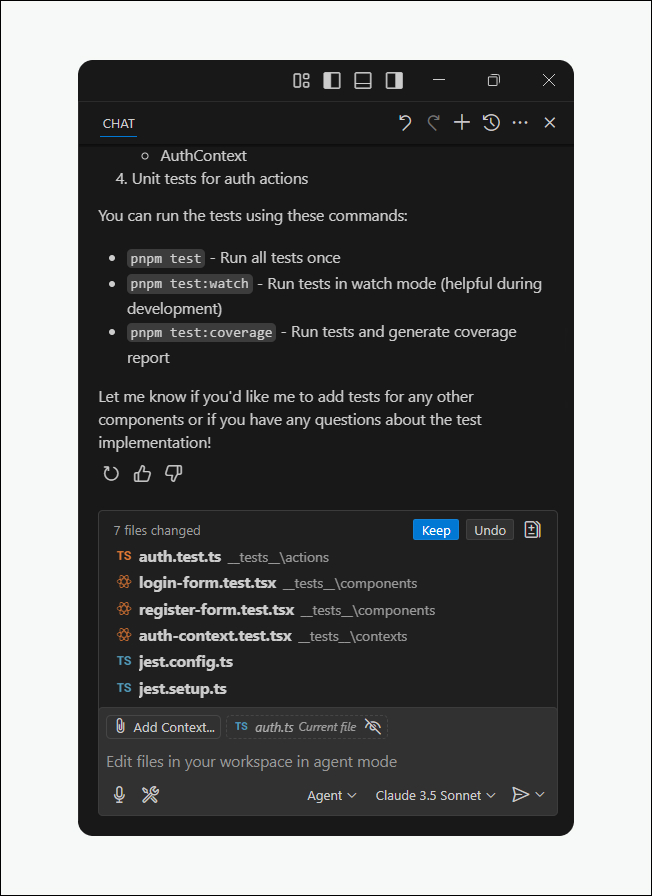
Image: Agent mode IDE supporting shift-left testing. Developers can write and run tests real-time while coding by simply delegating the task to the AI Agent.
Developer analytics and productivity engineering
As AI becomes more integral to coding and delivery workflows, engineering leaders turn to analytics-driven insights to understand and optimize team performance at scale. They will use tools like GitHub Insights, LinearB, or DX to assess productivity, quality, and velocity. What sets the next wave of engineering intelligence apart is AI-powered feedback loops. These systems interpret data in real time, offering suggestions to developers on how to write cleaner and faster code and effectively pair programming with telemetry.
Domain-specific languages and code abstraction
The developer’s focus is shifting from writing low-level logic to defining intent and outcomes. With this new paradigm, teams will increasingly rely on DSLs, AI compilers, and event-driven abstractions to accelerate system development.
- AI tools are increasingly capable of translating business requirements into technical implementations while maintaining domain boundaries.
- Future systems will likely excel at generating bounded contexts, identifying aggregates, and maintaining consistency across microservices architectures.
- The ability to reason about domain models and automatically enforce business rules through code generation will become particularly powerful.
What will future developers be looking at?
The future is clear: embrace this change, build the necessary skills, and step confidently into the role of AI orchestrator.
Developers will increasingly define and delegate tasks to intelligent agents, oversee outputs, and fine-tune results iteratively. Tomorrow’s most effective developers will approach AI not as competition, but as a force multiplier. Therefore, they should proactively expand their skill sets around prompt engineering, iterative design, and vibe coding.
The focus will shift from isolated functions to systems-level thinking, where developers act as designers of logic and stewards of architecture.
For CTOs and delivery leaders, this isn’t just a tooling upgrade; it’s a strategic transition. Success will depend on investing in AI upskilling programs and a supportive culture. The question isn’t whether this shift will happen, but how quickly you’re prepared to lead it.


AI in software testing transforms how software is planned, built, and maintained. It simplifies testing workflows, significantly enhancing productivity and efficiency across teams:
- For QA teams: automate regression tests, focus on exploratory work, and avoid script maintenance.
- For developers: accelerate test automation with a minimal learning curve.
- For business analysts & PMs: quickly create and run tests without coding or extensive training.
This blog explores how AI is helping Quality Assurance (QA) by speeding up test case generation, improving regression testing accuracy, and enhancing predictive test analysis.
→ More about how AI is transforming the Software Development Lifecycle (SDLC).
AI-driven methods in automation testing
AI in software testing brings speed, accuracy, and adaptability to an often-complex process. Let us look at a few AI-driven methods that help teams deliver value:
- Self-healing automation
Frequent code changes can break traditional test scripts, draining time and resources. With self-healing automation, AI instantly updates these scripts, reducing manual intervention and ensuring tests remain accurate as the application evolves.
- Intelligent regression testing
Validating old features after introducing new ones can be time-consuming. AI automates regression tests based on code changes, accelerating test cycles and freeing teams to focus on strategic, creative problem-solving.
- Defect analysis and scheduling
Machine learning identifies high-risk areas in the code and prioritizes critical test cases. This approach ensures testing efforts go where they matter most while intelligent scheduling optimizes resources for maximum efficiency.
Challenges and considerations in integrating AI in software testing
With AI-driven programming assistants like GitHub Copilot, Amazon CodeWhisperer, and Tabnine, teams can automate repetitive tasks, reduce human errors, and improve software quality while maintaining rapid release cycles. However, AI is not a silver bullet—it enhances workflows but still requires thoughtful integration into development processes. AI complements human expertise but isn’t a standalone solution. It excels in automation and pattern recognition but requires human oversight for context and judgment.
1. Data dependency
AI-driven testing thrives on vast, high-quality datasets. Poor training data may result in unreliable test recommendations. However, sourcing, curating, and maintaining these datasets is time-intensive, adding complexity to AI integration in software development.
2. Demand for skilled AI developers
AI enhances efficiency, but harnessing its full potential requires expertise. Skilled AI developers are essential to fine-tune models, interpret results, and optimize AI-driven testing. As demand for AI specialists rises, organizations face challenges acquiring the right talent to drive innovation.
3. Adapting to AI-driven workflows
Shifting from traditional testing to AI-based approaches requires flexibility. Teams accustomed to manual testing may hesitate to adopt AI tools. Training and real-world demonstrations help bridge this gap.
4. Safeguarding data and privacy
When sensitive information is involved, security and compliance become paramount. Especially in heavily regulated industries, teams must ensure the AI tools they use protect proprietary data and meet all legal requirements.
5. Addressing technical and resource needs
Deploying AI-driven testing at scale requires thoughtful investment. It may necessitate software upgrades or enhanced hardware capabilities. While AI adoption requires upfront investment in training and resources, its efficiency gains make it a strategic asset over time.
Key tasks that AI can automate
AI can quickly learn repetitive tasks and apply them across multiple workflows, reducing overhead and speeding up quality checks. These tasks include:
- Identify code changes and select critical tests to run.
- Automatically building test plans.
- Updating test cases whenever small code changes occur.
- Planning new test cases and execution strategies.
- Generating test cases for specific field types.
- Automating similar workflows after learning from one scenario.
- Deciding which tests should run before each release.
- Creating UI-based test cases for different components.
- Generating load for performance and stress testing.
Below is an example of using GenAI for WCAG accessibility checks. It generates multiple scenarios and elevates the overall quality of testing.
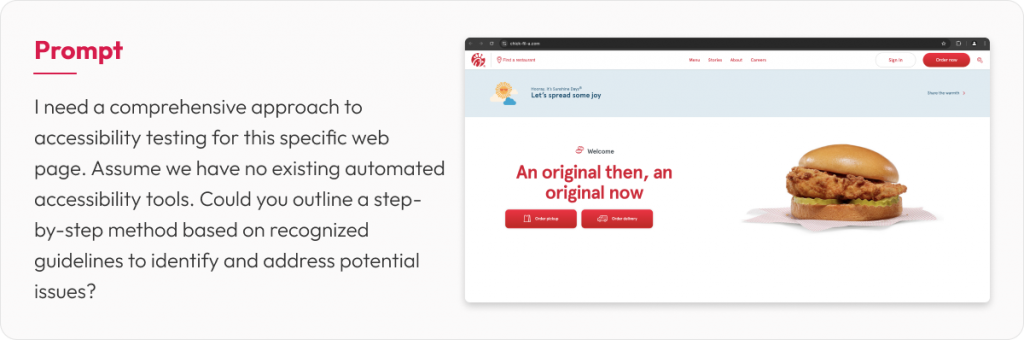

AI in unit testing: a game-changer for developers
One of the most impactful applications of AI in software testing is automated unit test generation. Writing unit tests is often deprioritized due to time constraints yet skipping them can introduce hidden defects. AI-driven programming assistants help by automatically generating comprehensive test cases, ensuring better test coverage without additional developer effort.
Tools such as TestGrade and LambdaTest are also expanding AI’s role in integration testing. By identifying potential issues before deployment, AI-powered automation reduces regression bugs and enhances overall software reliability.
AI in regression testing
Regression testing validates whether new code has unintentionally broken existing functionality, an essential safeguard as frequent releases become the norm. For CTOs managing large portfolios, this process often balloons in cost and effort with traditional, manual methods.
By integrating AI, enterprises dramatically cut the overhead of traditional regression testing. AI tools automatically identify test scenarios, generate scripts, and adapt to code changes, minimizing manual maintenance. Predictive analytics flag high-risk areas, letting teams focus on the most critical components. As a result, testing cycles become faster and more accurate, accelerating time-to-market while reducing overall costs and risk.
Using AI agents in software testing for greater efficiency
AI is entering a new phase defined by AI assistants (reactive systems that respond to user prompts) and AI agents (proactive systems that autonomously strategize and accomplish tasks). Agents handle tasks like test case generation, test execution, and issue identification. By leveraging NLP, these agents convert simple prompts into automated scripts and adapt to changes with self-healing features, reducing manual intervention and enabling continuous feedback in CI/CD pipelines.
Their real efficiency boost comes from running tests around the clock, in parallel, and at scale—covering more scenarios faster than any human team. By analyzing past data, AI agents pinpoint high-risk areas and optimize test coverage. The result is shorter test cycles, lower costs, and more reliable software releases that keep pace with evolving user and market demands.
The future of AI in testing: what’s next?
Looking forward, AI is set to become more sophisticated in software testing. Bug detection, code refactoring, and automated debugging are areas where AI will have a greater impact. We are also seeing early capabilities in AI-assisted language migration, where code can be translated from one programming language to another—such as Ruby on Rails to Java.
However, adopting AI tools should not be a knee-jerk reaction. It’s critical to select tools that align with development environments and technology stacks while ensuring they integrate seamlessly with existing workflows. AI adoption should be a strategic decision, not a reaction to industry trends.
Also check the following articles for a deeper dive into future:
Final thoughts
The role of AI in software testing should be seen as augmentative rather than a replacement for skilled testers and developers. While AI is still evolving, its future impact on software engineering will be profound.
Integrating AI in the software development life cycle isn’t just a technological upgrade. It’s a strategic shift that accelerates release cycles, reduces costs, and sustains quality across the SDLC. From automated test creation to intelligent bug detection, AI empowers QA teams, developers, and business stakeholders alike to move faster without sacrificing precision.
If you want to enhance your QA processes or learn more about practical AI applications in development, now is the time to explore your options. Whether pilot projects or full-scale adoption, our team can help you identify the best path forward to see a real, measurable impact on software quality.


AI in software development is reshaping how organizations navigate digital transformations. Yet many engineering teams, in their pursuit of agility and DevOps, find themselves bogged down by complexity, dependencies, and cognitive overload. As productivity stalls and time-to-market risks mount, AI in the software development lifecycle emerges as the critical enabler to drive enterprise value.
It takes sheer resilience to chase evasive bugs and manage the development process. Generative AI is changing this by making coding smarter and more efficient. Let’s explore how AI empowers teams to boost efficiency and gain insights once out of reach.
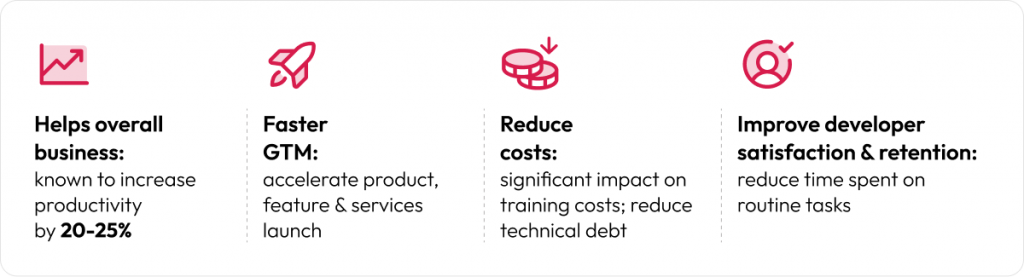
Impact of AI in software development
What does making an impact in software development really mean? As a developer, it is delivering maximum value to your customers while channeling your energy and innovation toward business goals. An effective environment streamlines the path to deploying high-quality software into production, preventing unnecessary complexities or delays. By removing friction and automating repetitive tasks, AI amplifies these benefits across the Software Development Life Cycle, freeing developers to focus on the value-adding work that truly drives impact. Let’s look at some of the ways AI is reshaping the SDLC.
AI in requirement gathering
Poorly managed requirements often lead to rework and cost overruns. AI-driven tools mitigate these risks by accelerating and refining the requirement-gathering process.
Tools like Jira AI Assistant seamlessly integrate with existing workflows to auto-generate user stories, maintain consistent formats, and break parent-level requirements into granular tasks. Meanwhile, GenAI uses inputs like project goals and personas to draft initial user stories, complete with acceptance criteria, desired outcomes, and dependencies.
AI in design
AI-powered design tools help us analyze and evaluate website and app design quality and usability. These tools help accelerate the design process, explore design options, and optimize UX. Design systems like Figma’s AI features can suggest component variations and styling options. Also, with AI plug-ins we can translate designs directly into code (HTML/CSS/React components) thus reducing the coding time for developers.
AI in coding
AI-powered tools like GitHub Copilot accelerate and enhance coding by offering suggestions, automating boilerplate code, and enforcing consistent standards. They free developers from repetitive work, letting them focus on complex problem-solving and innovation. By analyzing patterns from vast code repositories, these tools detect bugs early, suggest optimizations, and promote best practices. In doing so, they help maintain cleaner, well-documented code, reducing technical debt and boosting overall software quality and productivity.

Check out below podcast to discover insights from our hands-on experience with GenAI tools and how they enhance coding efficiency, optimize code quality, and streamline the development process.
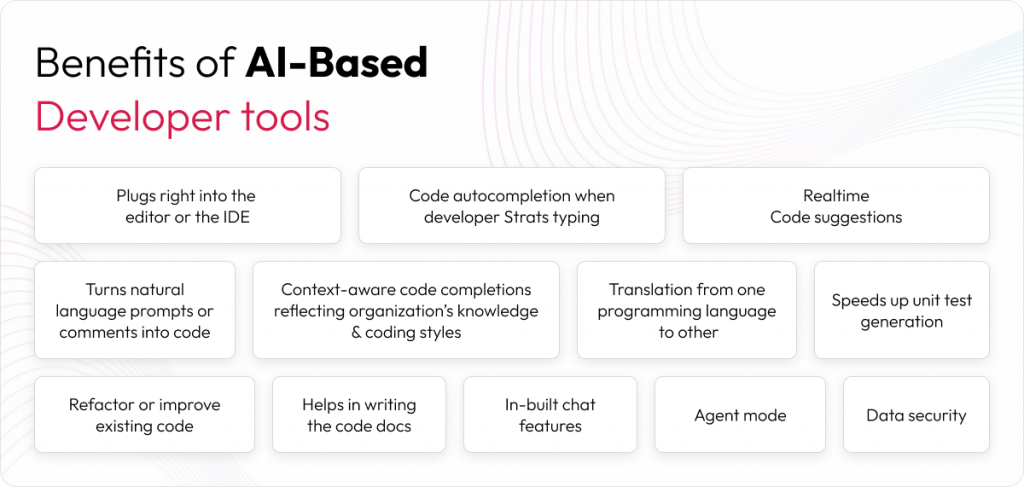
Benefits of AI based coding assistants
Accelerate coding speed: suggests code snippets, functions, and even entire blocks of code based on context, significantly reducing time spent on routine coding tasks.
Reduce cognitive load: handles boilerplate code and repetitive patterns, allowing developers to focus on higher-level problem-solving and architecture.
Improve code quality: can suggest best practices and help maintain consistent code style, potentially reducing bugs and improving maintainability.
Unit test generation: helps create unit tests, potentially increasing test coverage with less manual effort.
Context-aware assistance: understands the codebase context, providing suggestions relevant to the specific project rather than generic solutions.
Multi-language support: works across numerous programming languages and frameworks, making it versatile for different development environments.
Learning tool: helps developers discover new approaches, libraries, and patterns they might not have known about, serving as an educational resource.
Documentation: assists in writing code comments and documentation, encouraging better documentation practices.
Agent mode: in recent development, the code assistant can help you build apps in fully autonomous mode. So, it can break down complex tasks into manageable steps and implement solutions across multiple files or components with least intervention from developer. This is a big step towards achieving 90% to 100% AI Assisted coding in future.
Also check the following articles on Agentic AI:
AI in software testing
AI is transforming software testing with automated test case generation, intelligent bug detection, and enhanced API validations. Tools like ChatGPT and GitHub Copilot speed up test script creation and reduce repetitive tasks, improving overall test coverage and stability. By integrating these solutions into CI/CD pipelines, teams get rapid feedback and maintain higher-quality releases with reduced manual effort.
Unit testing with GitHub Copilot
A standout use case of AI-driven testing is automated unit test generation, where Copilot suggests targeted tests for edge cases, common inputs, and potential failure modes. This proactive approach to generating code scenarios significantly cuts down on development time. As a result, teams often see a 20–25% reduction in overall testing efforts, making AI a strategic investment that boosts reliability, reduces costs, and accelerates time-to-market.
AI in Continuous Integration/Continuous Deployment (CI/CD)
AI-driven solutions in CI/CD pipelines streamline and automate build and deployment processes. By using AI-enhanced Jenkins plug-ins, teams can detect deployment failures or performance regressions in real-time and automatically roll back to a stable build. Integration with AI-based monitoring tools such as New Relic, DataDog or Splunk enables proactive remediation when abnormalities arise.
AI capabilities in SonarQube provide continuous analysis of code, identifying bugs, vulnerabilities, and code smells. Over time, SonarQube learns from developer feedback, refining its rule set and prioritizing the most critical issues and helps getting AI-generated fix suggestions.
Key highlights
- Enterprises are increasingly leveraging AI to accelerate software delivery, enhance product quality, and unlock advanced insights.
- AI in software development streamlines requirement-gathering, design, coding, testing, and deployment, driving agility and reducing overhead.
- Tools like Jira AI Assistant and GitHub Copilot automate repetitive tasks, refine requirements, and accelerate coding, freeing developers to focus on complex problem-solving.
- Automated test generation and intelligent bug detection significantly lower testing efforts, boosting reliability and cutting time-to-market.
- AI-enabled CI/CD pipelines detect anomalies, trigger safe rollbacks, and optimize build steps, delivering faster, stable releases that enhance enterprise value.
Final thoughts
For organizations looking to integrate AI into their development and testing processes, the key is to focus on practical, measurable benefits rather than chasing the latest trends. Thoughtful implementation will ensure AI works as a force multiplier, enabling teams to build high-quality software with speed and precision.
Let’s continue the conversation. What has been your experience with AI in SDLC? Are you seeing measurable improvements in your development cycle? Connect with us to share insights.




