{kind=link}

Self-driving cars rely on machine learning (ML) algorithms that require large volumes of accurately labeled data to function safely and reliably. Most ML models used in the automotive industry today are supervised, which means they must be trained on annotated datasets that define and categorize real-world driving scenarios.
Data annotation enables autonomous vehicles to understand their surroundings, identify lanes, detect objects, and make split-second decisions. In the sections ahead, explore data annotation for autonomous vehicles and how labeled data supports the training of reliable AI models.
Just like a child who must first grasp basic concepts like circles, squares, and triangles to recognize shapes before diving into complex patterns, machines follow a similar learning curve. Machines require a way to decode and understand the data they receive. This is where data annotation comes in.
What is data annotation?
Data annotation is the practice of adding descriptive labels, tags, or classes to raw data so that a machine-learning model can understand what it is seeing, hearing, or reading.
In the context of autonomous driving, consider an image-recognition scenario where a folder of unlabeled street photos is nearly useless to an algorithm. Once each image is tagged with “pedestrian,” “traffic light,” or “truck,” the dataset gains meaning. The model can now associate patterns with real-world objects and predict them in new scenes.
What does data annotator do?
A data annotator plays a key role in preparing datasets for machine learning by labeling elements within raw data. This involves drawing bounding boxes around objects, highlighting regions of interest, tagging attributes, or classifying entities across various data types, such as images or LiDAR scans.
For example, annotators manually review thousands of frames from dashcams or street cameras to train a model to detect traffic lights, labeling each instance of a traffic light with precision.
Key object categories annotated for self-driving systems include:
- Vehicles (cars, trucks, motorcycles)
- Cyclists
- Pedestrians
- Traffic signs and signals
- Lane markings
- Road hazards like potholes, barriers, or construction zones
Types of annotations for autonomous vehicles
Accurate data annotation for autonomous vehicles depends on two primary sensor streams, camera images and LiDAR point clouds. Each stream demands specialized techniques to extract the detail an autonomous driving stack needs.
Image Annotation
Image annotation is the most common form of data annotation used in computer vision. It involves labeling objects or areas of interest within 2D images captured by vehicle-mounted cameras. Key image annotation methods include:
- Bounding Boxes: a widely used annotation method, bounding boxes are rectangular frames drawn around objects to define their position and dimensions clearly. This technique is extensively applied in object detection, training models to recognize pedestrians, vehicles, traffic signs, and other critical objects.
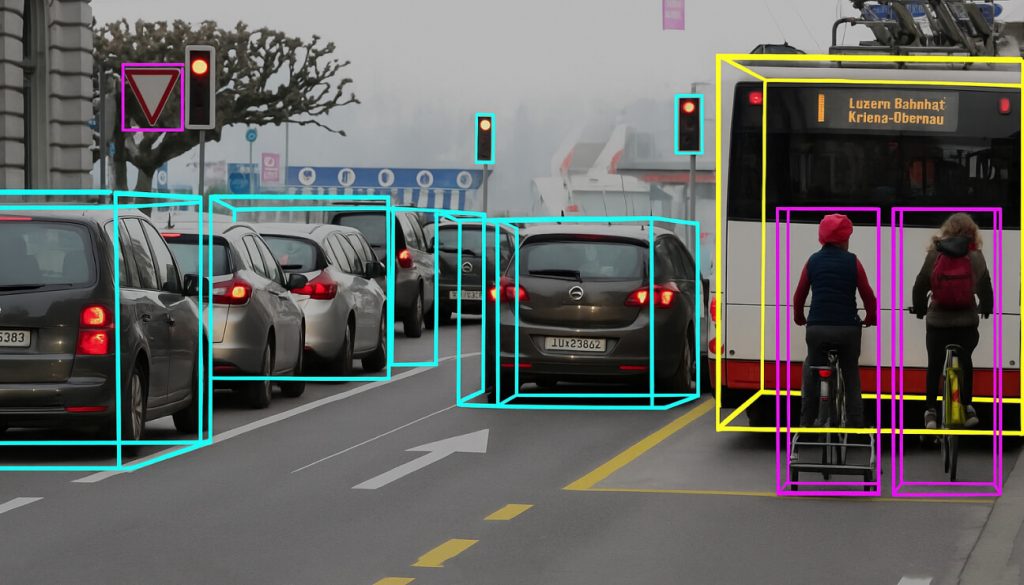
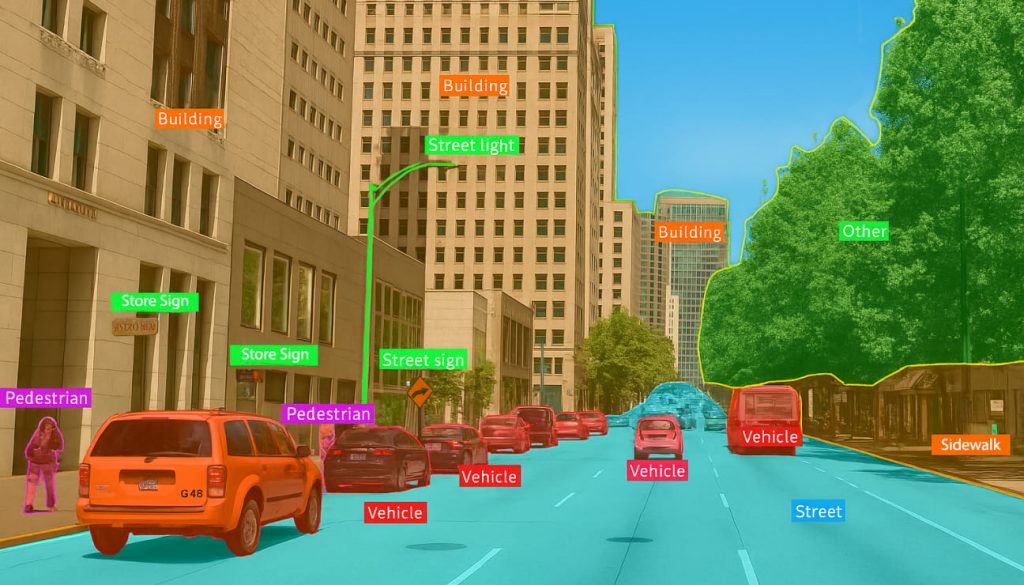
- Semantic Segmentation: it provides pixel-level annotation by assigning each pixel in an image a specific class label, such as road, sky, vehicle, or pedestrian. This detailed annotation enables autonomous systems to understand scene composition and make nuanced decisions, especially in high-density traffic or complex urban environments.
- Instance Segmentation: unlike semantic segmentation, which classifies object types, instance segmentation identifies and outlines individual objects, even when multiple items belong to the same class. For example, it distinguishes between two cars or pedestrians walking side-by-side. This is crucial for systems that can track and react to separate moving objects independently.

- Polygon Annotation: it allows annotators to define object boundaries using flexible, multi-point shapes—ideal for irregularly shaped or overlapping objects like trees, traffic islands, or curving lane markings. It delivers greater accuracy than bounding boxes in scenarios where object contours are critical.
LiDAR Annotation
LiDAR (Light Detection and Ranging) technology emits laser pulses to measure the distance and shape of objects, generating detailed 3D representations known as point clouds. Annotating LiDAR data enables self-driving cars to accurately perceive depth, location, and shape in three-dimensional space.
Key characteristics of LiDAR annotation include:
- LiDAR Point Clouds: LiDAR scanners collect vast datasets containing billions of individual data points, each with precise coordinates and reflective attributes. Annotators label these point clouds to distinguish vehicles, pedestrians, cyclists, road signs, and other critical features, facilitating robust spatial understanding and precise navigation.
- 3D Bounding Boxes (Cuboids): Similar to their 2D counterparts, 3D bounding boxes encapsulate objects within a three-dimensional space, providing essential information about their size, orientation, and location. These annotations are crucial for reliable object detection and accurate real-time obstacle avoidance.
Best data labeling tools
Selecting the right annotation platform accelerates your data annotation for autonomous vehicles workflow and ensures consistency across large teams, whether in-house or through data annotation outsourcing.
- CVAT: an open-source tool by Intel, offering bounding box, polygon, and semantic segmentation support for images and videos.
- Labelbox: a cloud-based platform with collaborative features, customizable workflows, and built-in QA modules for scalable annotation.
- VoTT (Visual Object Tagging Tool): a free, Microsoft-developed desktop app optimized for bounding box and rectangle labeling, with Azure integration.
- Xtream1: a comprehensive, enterprise-grade solution supporting multi-sensor (image, LiDAR) annotation and automated quality checks.
- CloudCompare: an open-source tool specialized for 3D point-cloud annotation, ideal for precise LiDAR labeling tasks in autonomous driving.
Your annotation team should also be proficient with any client-specific tools or proprietary platforms to maintain alignment with existing workflows and data formats.
Data labelling best practices
- Establish detailed annotation guidelines with standardized label definitions and update them regularly to cover new driving scenarios.
- Define a clear workflow → annotation, quality review, rework, final review, and delivery – with assigned roles and deadlines.
- Maintain a continuous feedback loop with clients to align on labeling expectations and minimize rework.
- Provide ongoing, project-specific training for annotators to ensure consistent understanding of tasks and tools.
- Perform regular manual QA checks using predefined checklists to identify and rectify annotation errors early in the process.
- Implement version control for annotated datasets to track changes, support audits, and simplify error tracing.
- Start with a pilot annotation phase on a representative dataset to refine guidelines and workflows before scaling up.
Our proven end-to-end data annotation workflow
Our data annotation services enable automotive clients to build high-quality datasets by following a well-defined, end-to-end workflow.
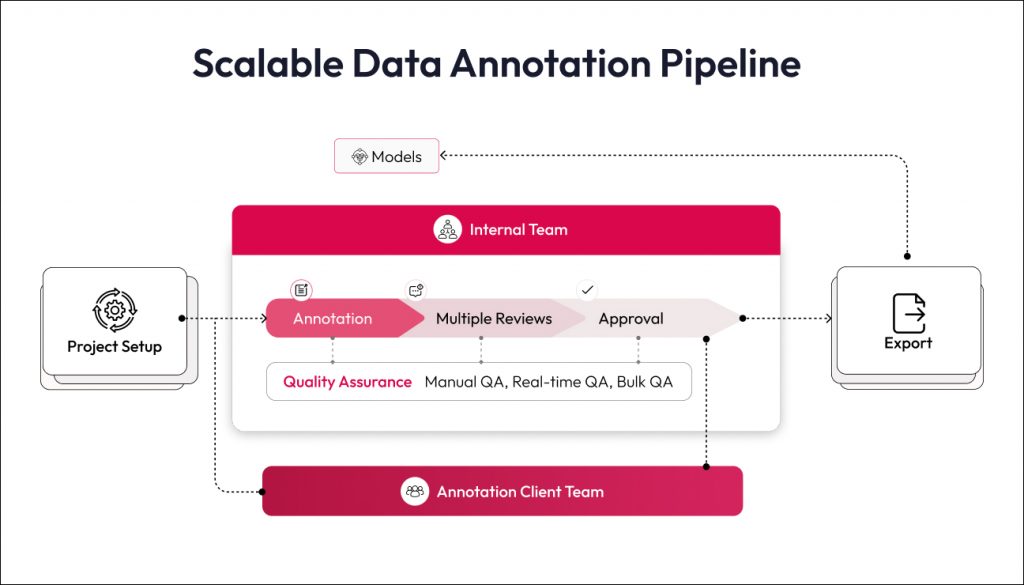
- Tool selection: we begin by choosing the optimal annotation platform for the project’s needs. The team evaluates whether to use industry-leading tools like Labelbox or CVAT, or a client’s in-house toolset. By aligning the tool choice with project requirements (e.g. support for 3D point clouds or specific export formats), we ensure smooth integration into the client’s development pipeline.
- Dedicated data annotation team: then we choose a dedicated team of experienced annotators and project leads who understand the nuances of automotive data. The team studies the client’s labeling guidelines in detail. Robosoft also provides thorough training sessions and even conducts a pilot project on a small data subset to confirm that guidelines are correctly interpreted.
- Semi-automated acceleration: where appropriate, pre-trained models generate initial labels for rapid review, and human annotators then correct and enhance these predictions to meet accuracy targets.
- Efficient annotation execution: throughout the annotation execution, we emphasize accuracy and consistency. Annotators follow the agreed-upon guidelines strictly, and complex edge cases are flagged for discussion so that the entire team handles them uniformly.
- Multi-level Quality Assurance: the process includes multi-level reviews of the annotated data. Senior annotators perform second-pass reviews on samples to catch any errors or inconsistencies. Any discrepancies are corrected, and feedback is looped back to the annotation team to prevent repeat issues.
- Delivery and ongoing support: final datasets are exported in the client’s preferred formats (COCO JSON, XML, PNG masks, etc.) and delivered in iterative batches to match development sprints. Post-delivery support includes update patches, re-annotation for new scenarios, and performance reviews.
Fueling the future of SDVs with data annotation services
The move to fully autonomous vehicles starts with understanding what is data annotation and ensuring every object, lane, and signal is labeled correctly. Without this foundation, AI models cannot achieve the precision required on today’s roads.
At Robosoft Technologies, we’ve partnered with leading OEMs to accelerate their transition to the Software Defined Vehicle (SDV) market. Our expert teams deliver accurate and secure data annotation services, leveraging advanced labeling techniques, best-in-class tools, and thorough quality checks. This ensures your autonomous driving projects receive the high-quality annotated data necessary to build reliable AI models and drive future innovation.





